

Mood and Variety: Recommendation System
I wanted to get some recommendations for movies that related to my current mood, not exactly the same, as the same stuff repeated again gets boring. So, I decided why not try to make one! It led to a discovery of amazing insights like what is nearer to children, christmas or superhero?
The system is a hybrid one with first content filtering, and then collaborative filtering using Singular Value Decomposition using surprise package in Python. The collaborative filtering is a standard one, but have tweaked on with the content filtering algorithm. The main motive was to have content filter that would not again bam with the exact same type of content, but a pleasant variation of it.
The data used is the MovieLens small data available at this link. It has around 100,000 ratings and 3,600 tag applications applied to 9,000 movies by 600 users.
All the code is available at my GitHub profile.
The data has 3 files:
- movies.csv: It contains the fields movieId, title, and genres of the movie.
- tags.csv: It contains userId, movieId, and tag.
- ratings.csv: It contains userId, movieId, and rating.
First, lets get started, read the tags and movies data, merge to put things together, in the code below:
import pandas as pd
import time
df_tags= pd.read_csv('data/tags.csv')
df_movies = pd.read_csv('data/movies.csv')
df_movies['genres'] = df_movies['genres'].apply(lambda x: x.split('|'))
df_tags_combined = df_tags.groupby('movieId').apply(lambda x: list(x['tag'])).reset_index().rename(columns={0:'tags'})
df_movies = pd.merge(df_movies, df_tags_combined, on = 'movieId', how = 'left')
df_movies['tags'] = df_movies['tags'].apply(lambda x: x if isinstance(x,list) else [])
df_movies['keywords'] = df_movies['genres']+df_movies['tags']
df_movies['keywords'] = df_movies['keywords'].apply(lambda x: set([str.lower(i.replace(" ", "")) for i in x]))
df_movies.set_index('movieId', inplace= True)
The df_movies dataframe now looks like this:
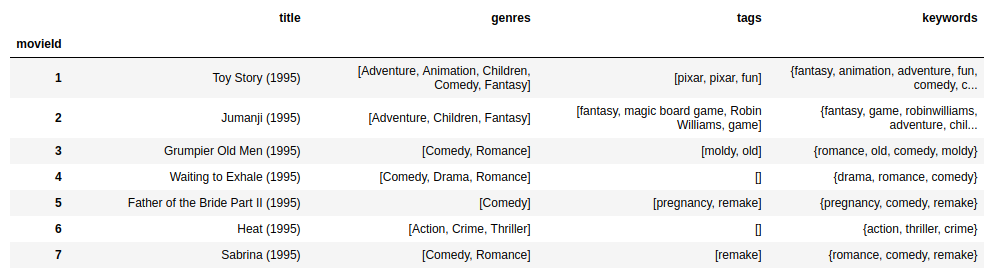
The tags and genres have been combined into keywords for each movie, not differentiating between the two. Now, the aim is to find the chief keyword of each movie: the keyword that has the most predictive power to determine the mean rating of that movie by all users. It is very tricky to do this. There can be various methods to do this, and I need to improve the model on this. For now, I am just using the feature importance of a decision tree regressor divided by the number of movies in which that keyword is present which I think is also giving reasonable results.
For that, first lets create a movies cross keywords dataframe, where each row is a movie and each column is a keyword, and the values are binary indicators indicating whether that keyword is present in that movie or not. We will also need to read the ratings data and get the mean_rating for each movie.
df_ratings = pd.read_csv('data/ratings.csv')
all_keywords = set()
for this_movie_keywords in df_movies['keywords']:
all_keywords = all_keywords.union(this_movie_keywords)
df_mxk = pd.DataFrame(0, index = df_movies.reset_index()['movieId'].unique(), columns = all_keywords)
df_mxk['mean_rating'] = df_ratings.groupby('movieId')['rating'].mean()
for index,row in df_mxk.iterrows():
df_mxk.loc[index,df_movies.loc[index]['keywords']] = 1
df_mxk['mean_rating'].fillna(df_mxk['mean_rating'].mean(), inplace=True)
df_mxk = df_mxk.loc[:,df_mxk.sum() > 5]
We have dropped the rare keywords that appear in less than 6 movies. The df_mxk dataframe looks like this:
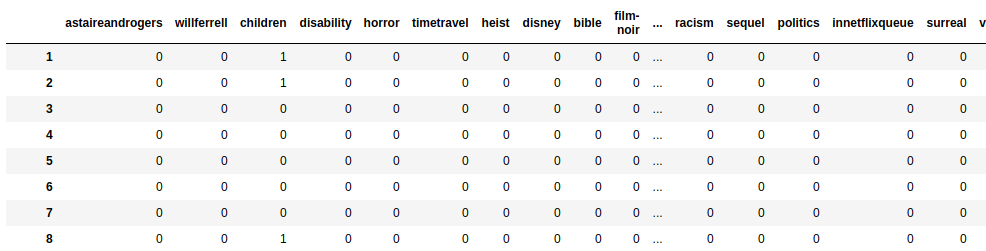
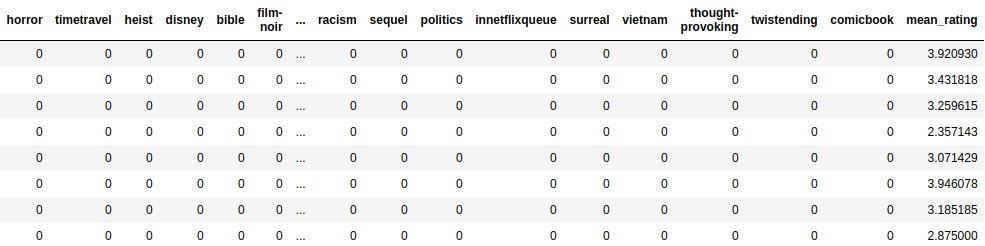
Next, lets use the Decision Tree Regressor and find the chief keyword of each movie.
from sklearn.tree import DecisionTreeRegressor
reg = DecisionTreeRegressor()
X = df_mxk.drop('mean_rating', axis = 1).as_matrix()
y = df_mxk['mean_rating'].as_matrix()
reg.fit(X,y)
keyword_scores = pd.Series(reg.feature_importances_ , index = df_mxk.drop('mean_rating', axis=1).columns)
keyword_frequency = df_mxk.sum()
df_movies['chief_keyword'] = df_movies['keywords'].apply(lambda x: (keyword_scores[x]/keyword_frequency).idxmax())
The df_movies dataframe now looks like this:
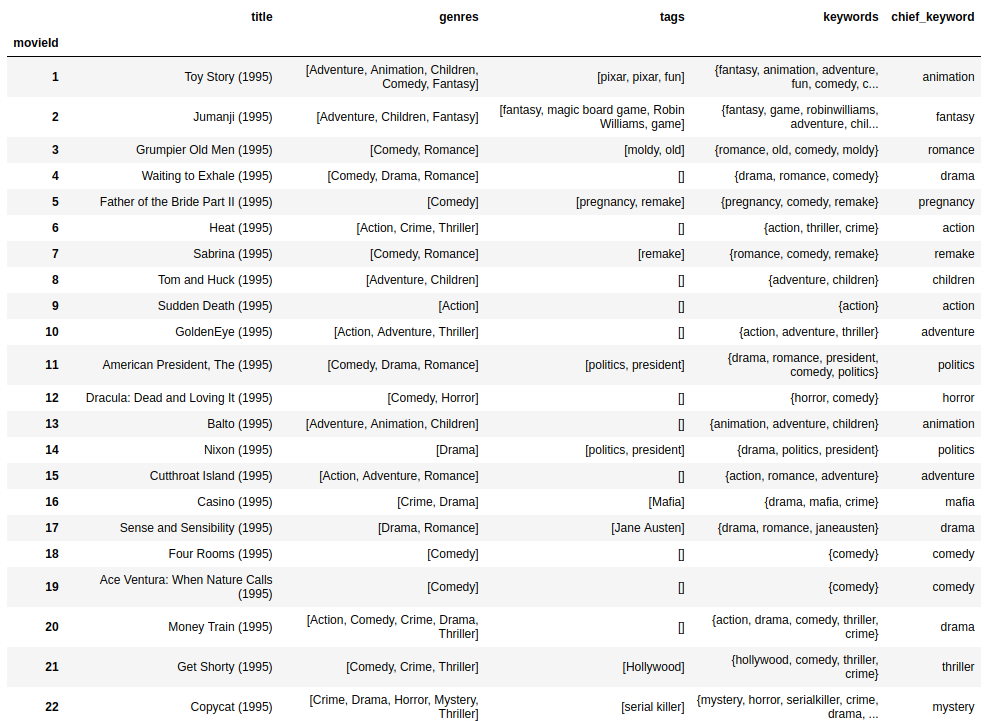
So, for example, it has been able to extract the chief keyword for movie Nixon as politics, chief keyword Mafia for movie Casino etc.
Next, the aim is to find a similarity score between different chief keywords and then use it for finding similarity scores between movies that will then be used for content filtering. Similarity scores have a very abstract meaning here, we are finding how much romance is similar to war, or action to drama etc. For this, we use the technique introduce by Ted Dunning in this link
The code steps are as follows:
- Create a user cross keyword matrix where value in each cell is cumulative sum of the rating given by that user to that chief keyword (or the movie that has that chief keyword) across all the movies rated by that user.
all_chief_keywords = df_movies['chief_keyword'].unique()
df_uxk = pd.DataFrame(0, index = df_ratings['userId'].unique(), columns = all_chief_keywords)
start = time.time()
for row in df_ratings.itertuples(index=True, name='Pandas'):
this_movie_chief_keyword = df_movies.loc[getattr(row, 'movieId'), 'chief_keyword']
this_user_this_movie_rating = getattr(row, 'rating')
this_user_id = getattr(row, 'userId')
df_uxk.loc[this_user_id,this_movie_chief_keyword] += this_user_this_movie_rating
end = time.time()
print 'Time Taken: '+ str(end-start)
2.Create a co-rating matrix where value in each cell is the cumulative sum of the pair wise minimum of all keyword combinations for each user across all users. It can best be understood by code:
nok = len(all_chief_keywords)
df_co_rating = pd.DataFrame(0, index = all_chief_keywords, columns = all_chief_keywords)
start = time.time()
for index,row in df_uxk.iterrows():
print index
for i, first_keyword in enumerate(all_chief_keywords):
for j in range(i+1,nok):
second_keyword = all_chief_keywords[j]
df_co_rating.loc[first_keyword,second_keyword] += min(row[first_keyword],row[second_keyword])
df_co_rating.loc[second_keyword,first_keyword] = df_co_rating.loc[first_keyword,second_keyword]
end = time.time()
print 'Time Taken: '+ str(end-start)
3.Create a similarity matrix using Ted Dunning method:
import scipy.stats
def sim_matrix(co): # returns the similarity matrix for the given co-occurence matrix
chief_keywords = co.columns
df_sim = pd.DataFrame(index = co.index, columns = co.columns)
f = co.sum()
n = sum(f)
for first_chief_keyword in chief_keywords:
for second_chief_keyword in chief_keywords:
k11 = co.loc[first_chief_keyword][second_chief_keyword]
k12 = f[first_chief_keyword]-k11
k21 = f[second_chief_keyword]-k11
k22 = n - k12 - k21 + k11
df_sim.loc[first_chief_keyword][second_chief_keyword], p, dof, expctd= scipy.stats.chi2_contingency([[k11,k12],[k21,k22]], lambda_="log-likelihood")
if ((k11/k21) < f[first_chief_keyword]/(n-f[first_chief_keyword])):
df_sim.loc[first_chief_keyword][second_chief_keyword] = 0
return df_sim
df_sim_chief_keyword = sim_matrix(df_co_rating)
A portion of the 120x120 similarity matrix looks like this:
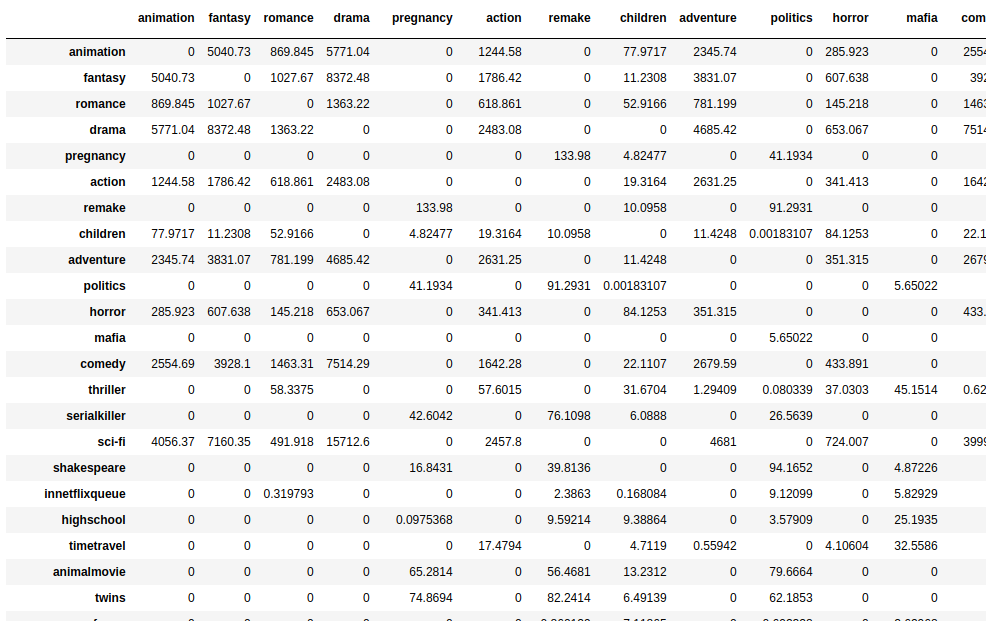
I am very pleased with the results for the long tail keywords. But, for keywords with very high frequency the results can be improved, and further work needs to be done. Five most similar chief keywords for some in order:
- highschool: music, christmas, willferrell, england, spoof
- mystery: adventure, drama, fantasy, sci-fi, war
- politics: prostitution, wedding, journalism, shakespeare, remake
- children: musical, christmas, western, horror, animation
- revenge: twistending, psychology, heartwarming, stephenking, martialarts
- leonardodicaprio: socialcommentary, drugs, stylized, kidnapping, cinematography
- superhero: timetravel, aliens, classic, western, revenge
- india: religion, adultery, divorce, moviebusiness, screwball
- creepy: serialkiller, depressing, kidnapping, philosophical, leonardodicaprio
- satire: witty, willferrell, twistending, funny, revenge
The results look extremely fascinating!
Now, lets go ahead and build the actual hybrid recommender and compare its results with only collaborative filtering recommender. Surprise package is the sci-kit learn for recommender systems. Lets import some modules from the surprise package and train the model on the ratings data. We will use the SVD (Singular Value Decomposition) algorithm introduced by Simon Funk during Netflix challenge for implementing collaborative filtering.
from surprise import SVD, Reader, Dataset
reader = Reader()
data = Dataset.load_from_df(df_ratings[['userId', 'movieId', 'rating']], reader)
data.split(n_folds=5)
svd = SVD()
trainset = data.build_full_trainset()
svd.train(trainset)
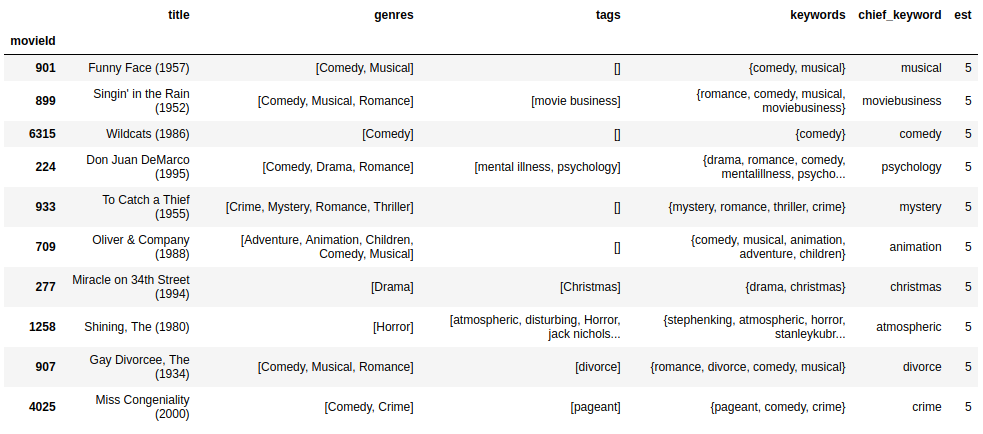
Now, lets generate predictions for user with userId 1 for the movie Spider-Man (2002). First, lets get the top ten recommendations from only collaborative filtering:
def collaborative(userId):
df_movies['est'] = df_movies['index'].apply(lambda x: svd.predict(userId,x).est)
return df_movies.sort_values('est', ascending=False).head(10)
collaborative(1)
Output:
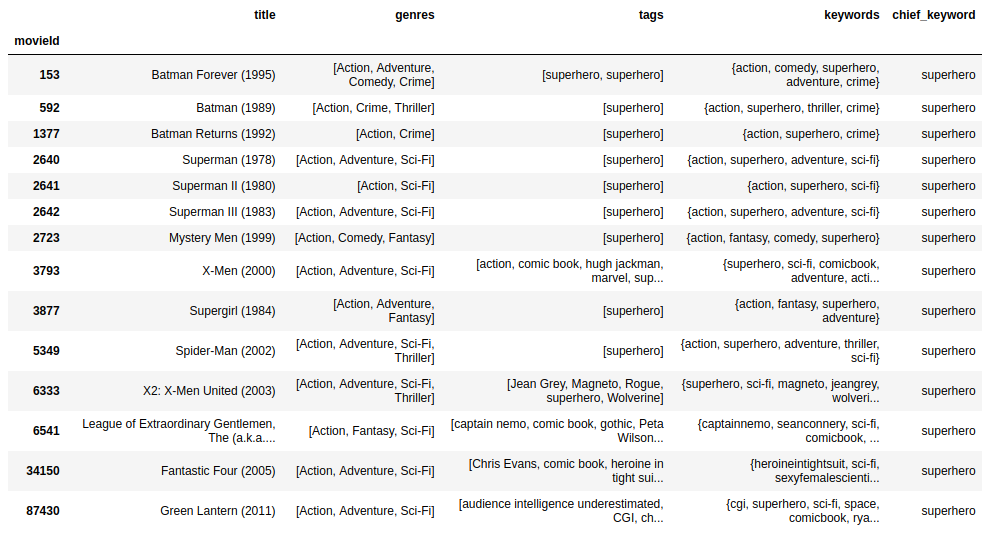
Now, lets fetch all the superhero movies from the dataset:
Now, lets create a hybrid recommender that first fetches the top 25 movies according to the similarity between chief keywords, and then applies collaborative filtering to get us the top ten.
title_to_id = df_movies.reset_index()[['movieId', 'title']].set_index('title')
def hybrid(userId, title):
this_movie_id = title_to_id.loc[title]
all_movieids = list(df_movies.index)
sim_scores_series = pd.Series(0,index = all_movieids)
for movieid in all_movieids:
sim_scores_series.loc[movieid] = df_sim_chief_keyword.loc[df_movies.loc[this_movie_id,'chief_keyword'],df_movies.loc[movieid,'chief_keyword']].iloc[0]
top_25_ids = sim_scores_series.sort_values(ascending=False)[:26].index
df_movies_top25 = df_movies.loc[top_25_ids].reset_index()
df_movies_top25['est'] = df_movies_top25['index'].apply(lambda x: svd.predict(userId,x).est)
#Sort the movies in decreasing order of predicted rating
df_movies_top25 = df_movies_top25.sort_values('est', ascending=False)
#Return the top 10 movies as recommendations
return df_movies_top25.head(10)
hybrid(1, 'Spider-Man (2002)')
Output:
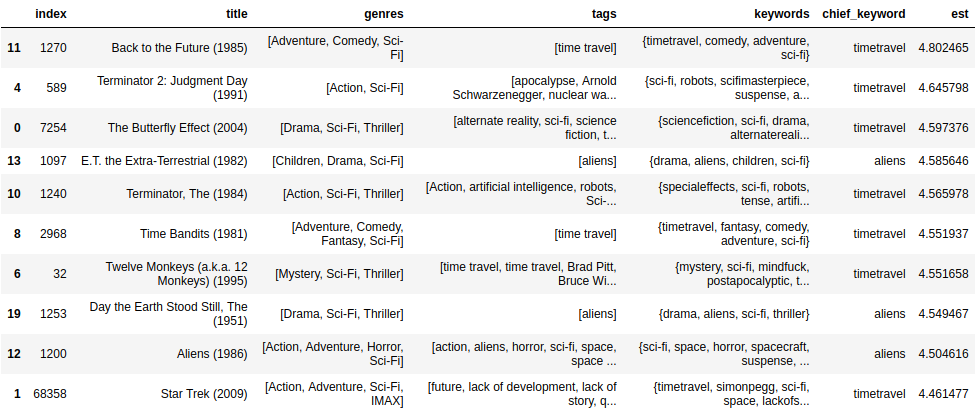
Here are my observations:
- The first list gives too much variety, it doesn’t match my current mood.
- The second list is too predicatble and boring. Mood wants to change gradually.
- The third list looks very interesting! It has Terminator, Star Trek etc. If we watch the trailer of these movies most people will be able to say that they are similar. It tries to give a balance between the mood delta and variety.
Hope you enjoyed! I haven’t watched Star Trek yet! See you again!